DynamoDB Stream 중복 처리 문제
DynamoDB Stream 은 Item 의 변경이 생겼을때 변경에 대한 Record 가 Stream 으로 전달되고, AWS Lambda , Kinesis Client 등으로 Record 를 전달 받아 Process 할 수 있는 기능이다.

kinesis client version => com.amazonaws:amazon-kinesis-client:1.14.4
Kinesis Client 를 사용하여 Stream Record 를 전달받는 경우, 아래와 같이 CheckPointer 를 사용하여 전달받은 Record 처리를 완료했다는 것을 알리게 된다.
@Override
public void processRecords(List<Record> list, IRecordProcessorCheckpointer iRecordProcessorCheckpointer) {
// do something
iRecordProcessorCheckpointer.checkpoint();
}
AWS 에서는 Process 를 처리한 후에 checkpoint 를 하기를 권장한다. 따라서, 아래 문서에 설명하고 있는 것 처럼 Process 를 진행한 후에 모종의 이유(배포)로 checkpoint() 가 호출되지 못 한 경우, 다른 Worker 가 해당 Lease 의 Owner 가 되면서 해당 Record 가 다시한번 처리될 가능성이 충분히 존재한다.
https://docs.aws.amazon.com/ko_kr/streams/latest/dev/kinesis-record-processor-duplicates.html
위와 같이 checkpoint() 가 호출되지 못하여 다른 Worker 가 해당 Record 를 처리하는 경우는 매우 짧은 시간에 발생하기 때문에 Record 의 순서를 보장하는 DynamoDB Stream 에서는 문제가 발생할 가능성이 매우 적다.
하지만, 아래와 같이 student 테이블의 데이터가 변경이 생겼을때 Stream 을 통해 count 를 집계하는 구조로 동작중인 아키텍쳐에서 student 테이블과 student_count 테이블의 데이터 불일치가 발생하여 원인을 파악하기 시작하였다.

불일치가 발생한 데이터가 발생한 시점에 특정 클라이언트의 네트워크의 문제가 있어서 약 12시간 동안 통신이 불가능했었다.

네트워크의 문제가 발생한 Worker 는 12시간동안 Stream 을 처리하지 못 하였고 당연히 또 다른 Worker 가 Lease 를 할당 받아 기존 Worker 에 문제가 발생한 시점부터 Record 를 처리하고 있었다.
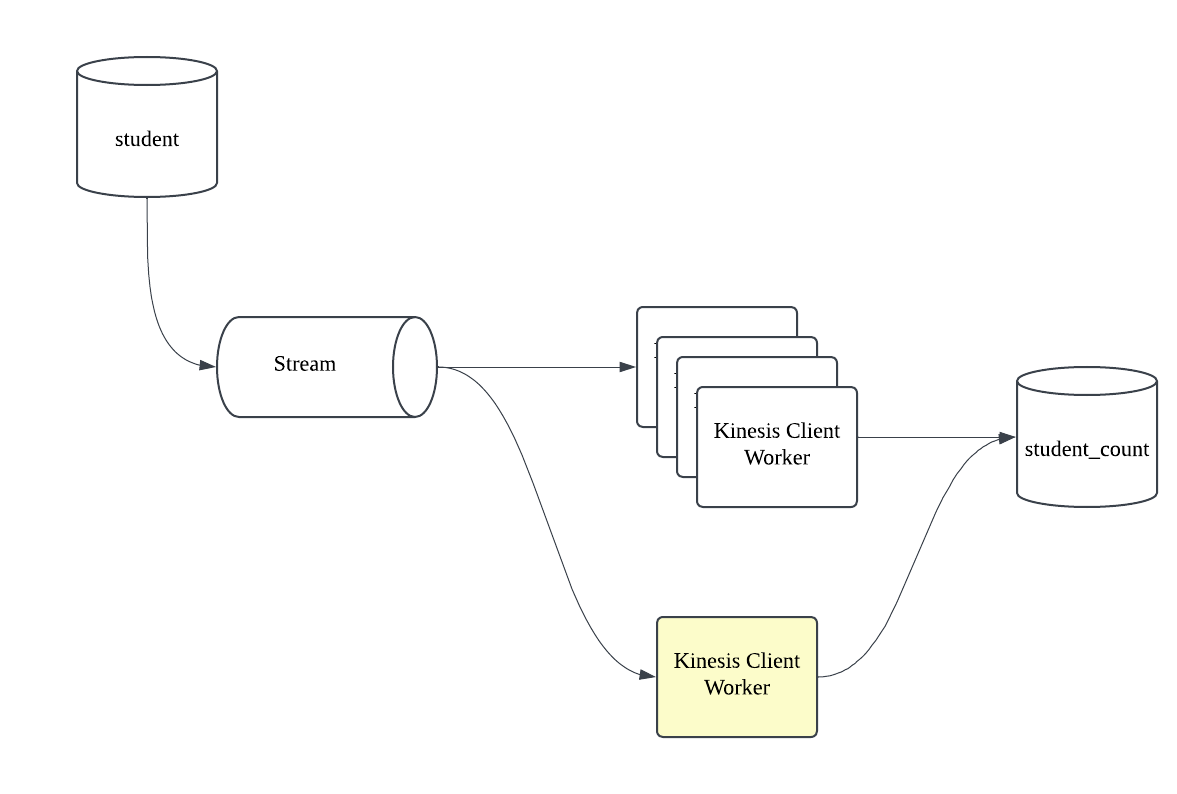
네트워크의 문제가 발생한 Worker 의 네트워크 문제가 해결되어 다시 통신이 가능해진 시점에, 네트워크에 문제가있던 시점인 12시간 전의 Record 를 읽어와서 처리하는 현상이 확인되었다. 12시간 전 데이터를 일부분만 가져와서 처리해버리니, student 테이블과 student_count 테이블의 데이터 불일치가 발생하게 된 것이다.
12시간 전 일부분 데이터만 읽어와서 처리하고 Worker 가 제거된 사유는 아래와 같다.
- 아래에서 설명할 이유로 12시간 이전 데이터를 읽어와서 처리함
- Stream Record 는 최대 1MB 의 데이터만 읽어올 수 있음. student 테이블의 Item 하나당 데이터 사이즈가 크기 때문에 150개 데이터만 Record 로 읽어올 수 있었음.
- checkpoint() 를 호출하였지만, 해당 lease 의 Owner 는 이미 다른 Worker 이므로 ShutdownException 발생
- ShutdownException 을 받고 Processor 종료.
네트워크 문제가 발생할 당시의 데이터를 복구된 후에 다시 불러온 이유
Kinesis Client 의 ProcessTask.getRecordsResult() 함수를 호출하여 Record 를 불러오게 된다.
private ProcessRecordsInput getRecordsResult() {
try {
return this.getRecordsResultAndRecordMillisBehindLatest();
} catch (ExpiredIteratorException var5) {
LOG.info("ShardId " + this.shardInfo.getShardId() + ": getRecords threw ExpiredIteratorException - restarting after greatest seqNum passed to customer", var5);
MetricsHelper.getMetricsScope().addData("ExpiredIterator", 1.0, StandardUnit.Count, MetricsLevel.SUMMARY);
this.dataFetcher.advanceIteratorTo(this.recordProcessorCheckpointer.getLargestPermittedCheckpointValue().getSequenceNumber(), this.streamConfig.getInitialPositionInStream());
try {
return this.getRecordsResultAndRecordMillisBehindLatest();
} catch (ExpiredIteratorException var4) {
String msg = "Shard " + this.shardInfo.getShardId() + ": getRecords threw ExpiredIteratorException with a fresh iterator.";
LOG.error(msg, var4);
throw var4;
}
}
}
네트워크가 복구될 당시에 ExpiredIteratorException 이 대량 발생하였고, 해당 예외가 발생하였을때 Iterator 값을 LagestPermittedCheckpointValue 로 변경하는 것을 확인할 수 있다.
final ProcessRecordsInput processRecordsInput = getRecordsResult();
throttlingReporter.success();
List<Record> records = processRecordsInput.getRecords();
records = deaggregateRecords(records);
recordProcessorCheckpointer.setLargestPermittedCheckpointValue(
filterAndGetMaxExtendedSequenceNumber(scope, records,
recordProcessorCheckpointer.getLastCheckpointValue(),
recordProcessorCheckpointer.getLargestPermittedCheckpointValue()));
LargestPermittedCheckpointValue 값은 getReordsResult() 한 결과를 저장하는 것을 볼 수 있다.
즉, ExpiredIteratorException 이 발생할 경우 해당 Worker 가 마지막으로 불러온 Record 의 Checkpoint 를 로컬에 저장하고 있다가 그 지점부터 다시 Record 를 불러오는 것이다.
이로인해, 네트워크가 복구된 시점에 네트워크에 문제가 발생할 시점의 Record 를 다시 처리하게 되었고 그 결과 두 테이블간의 데이터 불일치가 발생하였다.
해결방법
- student_count 테이블을 처리하는 로직에서 중복 처리를 방지.
- 이미 Worker 가 많은 Stream 을 처리하고 있다면 하나하나 적용하기 힘듬
- Processor 가 DB 에 저장하는게 아니라면, 중복 처리를 방지하는데 한계가 있음. ex) Kafka message 발행
- Record.getApproximateArrivalTimeStamp() 값이 특정 시간 이후라면, 유효하지 않은 Record 로 판단하고 Processor 에서 처리하지 않고 Skip
- 만약 Processor 의 처리가 지연되면서 적용한 조건보다 Processor 가 받은 Record 시간이 길어진다면 정상 Record 를 처리하지 않게되는 문제 발생
- Lease Table 에 접근하여 Owner 가 현재 Worker 인지 확인
- Record 를 처리하기위해 매번 Lease 테이블에 접근하는건 매우 비효율적.