Cassandra db - Partitioning 과 Replication
Dynamo
카산드라는 분산형 Key-value 시스템인 Amazon 의 Dynamo 에 많은 기능들을 의존한다. Dynamo 시스템의 각 노드들은 아래와 같은 세개의 주요 요소가 있다.
- 분할된 Datset 에 대한 조정 요청
- Ring 멤버십과 실패 탐지
- Local 의 지속 저장 엔진
카산드라는 Log Structured Merge Tree(LSM) 기반의 스토리지 엔진을 사용하면서 위에서 두가지 클러스터링 요소들을 주로 이끌어냈다. 특히 카산드라는 Dynamo 의 아래 스타일들을 의존한다:
- 변하지 않는 Hashing 을 사용한 데이터 Partitioning
- 버전으로 관리된 데이터를 사용하는 Multi Master
- Gossip 프로토콜을 사용하여 실패 탐지와 분산 클러스터 멤버십
- 하드웨어의 증분 scale out
카산드라는 큰 규모에 적합하도록 설계되었다. 특히 Application 이 read, write 에 낮은 latency 가 필요해지고 전역의 Replication 이 필요해짐에 따라, 기존 관계형 Database 는 scaling 에 적합하지 않기 때문에 반드시 새로운 종류의 Database 모델이 디자인 되어야 했다.
Dataset Partitioning: Consistent Hashing
카산드라는 모든 데이터를 Hash 함수를 사용하여 저장함으로 수평적인 확장성을 얻을 수 있었다. 종종 랙과 Datacenter 자체의 문제와 같은 장애가 발생하기 때문에 각 Partition은 여러개의 물리 노드에 나누어져 복제된다. 모든 복제본은 독립적으로 이것이 가지고 있는 모든 키에 대해 돌연변이를 받아들일 수 있기 때문에 모든 키는 버전이 있어야 한다. 원래 Dynamo 가 버전을 결정하고 동시에 발생하는 Key 업데이트를 받아들이기 위해 Vector 시계를 사용하는것과 달리, 카산드라는 마지막에 쓰여진 버전을 사용하는 간단한 모델을 사용한다. 공식적으로 언급되기를, 카산드라는 Last-Write-Wings Element-Set Confilict Free 복제 타입을 각 CQL Row 에 사용한다.
Consistent Hashing using a Token Ring
카산드라 Parition 데이터는 Consisent Hashing 이라고 불리는 특별한 형태를 사용하고있다. 고지식한 Data Hashing 에서 너는 Key 의 Hash 값의 나머지 값으로 각 Bucket 에 키를 위치시켰다. 예를들어 고지식한 Hashing 방법을 사용하여 100개의 노드에 데이터를 분산하고 싶다면, Hash 값을 100으로 나눈 나머지 값을 각 버켓에 저장했을 것이다. 하지만 이 방법에 Node 를 추가하게 되면 이전에 저장된 Key 들은 유효하지 않게 된다.
대신에 카산드라는 모든 노드를 하나 이상의 연속적인 hash ring 의 토큰에 맵핑 시키고 Chord 알고리즘과 비슷하게 Hashing Key 기반으로 Ownership 을 정의하고 한 방향으로 Hash Ring 을 "Walking" 하도록 한다. 고지식한 Hashing 과 Consistent Hashing 방법의 주된 차이점은 Hash 를 가지고 있는 Node 의 숫자가 변경되면 Consistent Hashing 은 Key 의 작은 파편들만 이동하면 된다는 것이다.
예를들어, 8개의 key 를 가지고 있는 노드로 구성된 클러스터가 있고 3개의 복제본이 저장되고, Key 를 가지고 있는 노드를 찾는다고 할때 찾고자하는 Key 를 Hash 하여 Token 을 생성한다. 그리고나서 Ring 을 시계방향으로 "Walk" 하여 Key 의 모든 복제본인 3개의 구분된 노드를 만날때까지 지속한다. 아래 그림은 8개의 노드, 3개의 복제본에 대한 그림이다.

Dynamo 와 같은 시스템에서 Token Range 라고 알려져 있는 Key 범위를 사용하는 기술같은 모습을 볼 수 있다. 예를들어 토큰 1을 제외하고 토큰2를 포함하는 토큰 범위에 속하는 모든 키는 노드 2, 3, 4에 저장된다. 쉽게 말해 토큰 범위가 1-800이고 노드가 8개 이면 1-100 까지의 토큰은 첫번째 노드, 101-200의 토큰은 두번째 노드에 저장된다는 것이다.
Multiple Tokens per Physical Node (vnodes)
간단한 단일 토큰을 사용하는 Consistent Hashing 은 데이터를 분배하는 물리 노드가 많은 경우에 잘 동작한다. 하지만 일정한 간격의 토큰과 적은 수의 물리 노드의 경우에 Scaling ( 용량을 위해서 몇개의 노드를 추가할 경우 ) 이 어렵다. 왜나하면 링이 균형을 유지할 수 있는 새 노드에 대한 토큰 선택이 없기 때문이다. 카산드라는 토큰의 불균형을 피하고자한다. 왜냐하면 토큰이 불균형을 이루게되면 요청의 양 또한 불균형해지게 된다. 예를들어, 이전 예제에서 9번째 토큰을 불균형없이 추가할 수가 없다. 대신에 기존에 존재하는 범위의 중간에 8 토큰을 삽입해야한다.
Dynamo paper 는 "Virtual Nodes" 를 사용하여 이 불균형 문제를 해결하려고 한다. Virtual Nodes 는 물리노드 하나에 여러개의 Token 을 할당함으로서 이 문제를 해결한다. 단일 노드가 Ring 에서 여러개의 위치를 점유할 수 있도록 함으로서 작은 클러스터가 더 커보이도록 할 수 있고 하나의 노드가 여러개의 노드처럼 동작할 수 있도록 한다. 이는 단일노드를 추가할 때 더 많은 링의 이웃으로부터 많은 작은 데이터를 효과적으로 가져옵니다.
카산드라는 몇몇의 명명법으로 이 개념을 소개합니다.
- Token: Dynamo 스타일의 Hash Ring 에서 단일 포지션
- Endpoint: 네트워크에서 단일 물리 IP 와 Port
- Host ID: 단일 "물리" 노드를 식별하기위한 식별자, 보통 하나의 Endpoint 와 하나 이상의 Token 을 포함
- Virtual Node (or vnode): Hash Ring 에서물리 노드에 의해 점유된 토큰
Token 과 Endpoint 의 맵핑은 Token Map 에 저장되어있다. Token Map 은 어떤 물리 endpoint 가 Ring position 에 연결되어있는지를 카산드라가 지속적으로 추적한다. 예를들어, 아래 그림에서 볼 수 있듯이 4개의 물리 노드를 사용하지만 물리 노드 하나당 2개의 토큰을 할당함으로서 8개의 노드로 구성된 클러스터를 구성할 수 있다.
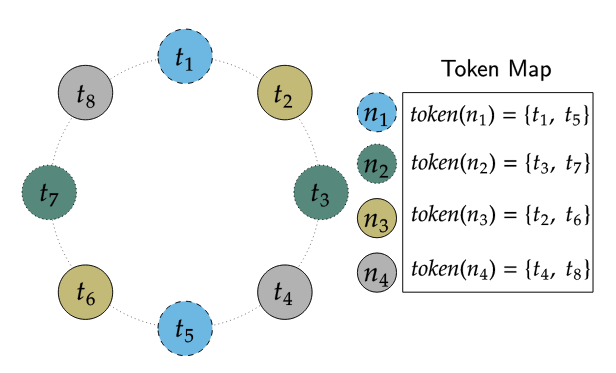
물리 노드에 여러개의 토큰을 할당함으로서 얻을 수 있는 장점들은 아래와 같다:
- 새로운 노드가 추가될때 대략적으로 동일한 양의 데이터가 다른 Ring 의 노드로부터 전달된다. 그 결과로 클러스터 전체적으로 비슷한 데이터가 각 노드에 분산된다.
- 노드가 제거될때 클러스터의 다른 노드와 대략적으로 비슷한 크기의 데이터가 사라지게 되므로 클러스터 전체적으로 비슷한 데이터 양이 각 노드에 분산된다.
- 노드가 어떤 문제로 인해서 가용할 수 없는 상태일때 다른 많은 노드들에 의해서 요청이 분산되고 처리될 수 있다.
그러나 Multiple 토큰은 단점 또한 존재한다:
- 모든 토큰은 2 * (RF - 1) 까지 추가적으로 Ring 에 이웃이 존재해야한다. 이는 토큰 링의 일부에 대한 가용성을 상실하는 노드 실패조합이 더 많다는 것을 의미한다. 토큰이 많아질수록 장애의 가능성이 높아진다는 것이다.
- 클러스터 유지를 위한 수행이 느려진다. 예를들어 각 노드에 할당된 토큰이 많아질수록, 보수를 위한 수행 또한 증가한다
- 토큰 범위에 따른 수행의 성능 또한 영향을 받는다.
카산드라 2.x 버전에서는 Picking Random 알고리즘만 사용가능하다. 이는 균형을 유지하기 위하여 각 노드별 기본 Token 의 수가 꽤 높다는 것을 의미한다. 이로인해 많은 물리 노드가 함께 묶이는 영향이 있고 그로 인해 장애의 위험이 높아진다. 이것이 3.x 이상 버전에서 새로운 토큰 할당을 위한 결정성이 추가된 이유이다. 새로운 토큰 할당 기능이 각 노드별로 더 낮은 갯수의 토큰이 할당되도록 똑똑하게 토큰을 고른다.
Multi-master Replication: Versioned Data and Tunable Consistency
카산드라는 고가용성과 내구성을 위하여 모든 Parition 데이터를 많은 노드에 복제한다. 변화가 발생하였을때 Coordinator 가 Parition Key 를 해쉬하여 데이터가 속할 토큰 범위를 결정한다. 그리고나서 Replircation Strategy 에 따라서 그 변화를 각 노드로 복제합니다.
모든 복제 전략은 Replication Factor (RF) 라는 개념을 가지고 있다. RF 는 해당 파티션의 복제품을 몇개를 가지고 있어야 할지를 가리킨다. 예를들어 RF=3 인 Keyspace 라고 한다면, 데이터는 3개의 구분된 Replica 에 저장된다. Replica 는 항상 구분된 물리 노드에 선택되어 저장된다 하지만 필요에 따라서 Virtual Node 는 건너뛸 수 있다. Replication Strategy 는 카산드라 클러스터 전체 랙 또는 노드 데이터 센터의 오류로 발전되지 않도록 문제가 있는 랙 또는 데이터 센터를 건너뛰도록 설정할 수 있다.
Replication Strategy
카산드라는 주어진 토큰 범위에서 어떤 물리 노드에 복제 데이터를 저장할지 결정하기 위해서 Replication Strategy 를 제공한다. 모든 데이터의 Keyspace 는 Replication Strategy 가 지정되어있다. 모든 운영에 배포되는 카산드라는 NetworkTopologyStrategy 를 사용할 것이 권장되며 SimpleStrategy 전략은 테스트를 위한 클러스터에 유용하다.
NetworkTopoplogyStrategy
이 전략은 클러스터의 각각의 datacenter 에 복제 요소가 필요하다. 단일 Datacenter 를 사용하는 클러스터라고하더라도 NetworkTopoplogyStrategy 는 새로운 물리 datacenter 또는 가상 datacenter 를 쉽게 추가할 수 있기 때문에 SimpleStrategy 보다 선호된다.
게다가, datacenter 별로 각각의 Replicatiion Factor 를 허용하기위하여 NetworkTopologyStrategy 는 또한 Snitch 에 의해 명시된 Datacenter 내의 다른 Rack 의 Replica 를 고르도록 시도한다. 만약 Rack 의 숫자가 Replica 보다 크거나 같은 경우에는 각각의 Replica 는 서로 다른 Rack 으로부터 선택될 것을 보장한다. 반면에 각 Rack 은 적어도 하나의 Replica 를 갖게되지만 하나 이상을 가지게 되기도 한다. 이러한 랙 기반 동작은 잠재적으로 놀라운 영향을 미칠 수 있다. 예를들어 각 Rack 에 짝수의 노드가 없는 경우, 가장 작은 Rack 의 데이터 로드는 꽤 높아진다. 비슷하게 새로운 Rack 에 단일 노드가 수동된다면, Ring 전체의 Replica 로 고려될 수 있다. 이러한 이유로 많은 관리자들은 모든 노드를 단일 가용존 또는 단일 Rack 으로서 비슷한 장애 도메인으로 설정한다.
SimpleStrategy
이 전략은 replica_factor 라는 값을 설정하도록 한다. 이 것은 각 Row 의 복사본을 몇개의 노드가 가져야 할지를 결정한다. 예를들어 replication_factor 가 3 인 경우에 3개의 서로 다른 노드가 각 Row 의 복사본을 갖게 된다.
SimpleStrategy 는 모든 노드를 동등하게 다루기 때문에 datacenter 또는 Rack 설정을 무시한다. Token Range 에 따른 복제를 결정하기위하여 카산드라는 관심 토크 범위에서 시작하여 링의 토큰을 반복한다. 각 토큰은 토큰을 소유한 노드가 추가되어야 하는지 확인을하고 추가가 안되어있다면 추가를 한다. 이 과정은 repliaion_factor 만큼의 Replicaion 이 추가될때까지 반복된다.
Data Versioning
카산드라는 데이터의 일관성을 보장하기 위하여 변경 타임스탬프 versioning 을 사용한다. 특히 카산드라에 가해지는 모든 변경은 Client 에서 제공하는 시간을 사용하거나 또는 노드 자체의 시간을 제공한다. 업데이트에 따른 충돌은 나중에 쓰여진 쪽이 사용되도록 하여 해결한다. 카산드라의 정확성은 이 시간에 의존되기 때문에 NPT 와 같은 적절한 시간동기화 프로세스가 동작해야한다.
카산드라는 CQL paritioon 안에 모든 Column 의 모든 Row 에 분리된 변경 타임스탬프를 적용한다. Row 는 Primary Key 에 따라 유일한것이 보장되며 Row 안의 각 Column 은 Last-Write-Wins 정책에 따라서 충돌을 해결한다. 이것은 Parition 안에 다른 Primiary Key 의 업데이트를 충돌없이 해결할 수 있다는 것이다. 게다가 Map 과 Set 과 같은 CQL 의 Collection 타입은 이러한 충돌 없는 메커니즘을 사용하여 동시에 업데이트되었을때 발생할 수 있는 문제를 해결한다.
Replica Synchronization
카산드라의 Replica 는 독립적으로 변화를 받아드릴 수 있기 때문에, 어떤 Replica 에는 새로운 데이터가 저장되어있지만 또 다른 Replica 에는 이전 데이터가 저장되어있을 수 있다. 카산드라는 Replica 데이터를 하나로 수렴시키기 위하여 많은 노력을 기울인 기술들이 존재한다. (Realica read repiar <read-repair> , Hinted handoff <hints>)
그러나 많은 노력이 들어갔지만 카산드라는 Merkle Tree 라고 불리는 Hash-Tree 를 계산하여 일치하지 않는 데이터가 있는지 비교하는 anti-entropy repiar <repiar> 를 구현하였다. 기존 Dynamo paper 와 같이 카산드라는 Merkle Tree 를 생성하고 일치하지 않는 범위에 있는 데이터를 동기화 시킨다.
기존 Dynamo paper 와 달리 카산드라는 또한 sub-range 보수와 점증적 보수를 구현하였다. Sub-Range 보수는 카산드라가 더 큰 Hash Tree 를 생성함으로서 Hash Tree 의 해결을 증가할 수 있도록 한다. 점증적 보수는 카산드라가 마지막 보수 이후 변경된 파티션만 보수할 수 있도록 한다.
Tunable Consistency
카산드라는 Consistency Level 을 통하여 일관성과 가용성을 제공한다. 카산드라 Consistency Level 은 Dynamo 의 R+W>N Consistence 메커니즘 버전이다. 사용자는 Read(R) 에 참가할 노드의 갯수를 설정할 수 있고 Write(W) 에 참가할 노드의 갯수를 설정할 수 있다. 이는 Replication Factor(N) 보다 작아야 한다. 카산드라에서 Replication Factor 와는 상관 없이 R 과 W 를 선택할 수 있다. 일반적으로 Read 의 Consistency Level 이 Write Consistency Level 과 함께 과반 이상의 상호작용이 보장된 추분한 노드를 보장한다면 쓰기 이후에 읽기가 가능하다.
사용 가능한 Consistency Level 은 아래와 같다:
- ONE : 오직 하나의 단일 Replica 가 응답해야한다
- TWO : 두개의 Replica 가 응답해야한다.
- THREE : 세개의 Replica 가 응답해야한다.
- QUORUM : 과반 (n/2 + 1) 의 Replica 가 응답해야한다.
- ALL : 모든 Replica 가 응답해야한다.
- LOCAL_QUORUM : Local datacenter 에 과반 이상의 Replica 가 응답 해야한다.
- EACH_QUORUM : 각 datacenter 의 주요 Replica 가 응답 해야한다.
- LOCAL_ONE : 오직 하나의 단일 Relica 가 응답 해야한다. Read 요청이 Remote 의 Datacenter 로 전달되지 않는 것이 보장된다.
- ANY : 단일 Replica 가 응답하거나 Coordinator 가 Hint 를 저장하고 있다. 만약 힌트가 저장되어있다면 Coordinator 는 힌트를 다시 확인할 것을 시도하고 Replica 에게 변경을 전달한다. 이 Consistency Level 은 오로지 Write Operation 에 한해서 받아드려진다.
Write 명령은 Cosistency Level 과 관련없이 항상 모든 Replica 에게 전달된다. Consistency Level 은 Client 에게 응답하기 전에 얼마나 많은 응답을 Coordinator 가 기다려야할지를 결정한다.
Read 명렁에 대하여, Coordinator 는 일반적으로 Consistency Level 을 만족시키기 위한 만큼의 Replica 에게 Read 명령을 전달한다. 단 하나의 예외는 특정 시간동안 기존의 Replica 가 응답을 하지 않는다면 여분의 Replica 에게 Read 명령을 재시도한다.
Picking Consistency Levels
Write 이후에 Read 를 하기 위하여 Read 와 Write 의 Consistency Level 을 선택하는 것은 일반적이다 . 전형적으로 Dynamo 에서는 같은 용어로 표현되었다 W+R > RF. 예를들어 만약 RF = 3 일때 QUORUM 요청은 적어도 2/3 의 Replica 로부터의 응답이 필요하다. 만약 QUORUM 이 Read 와 Write 에 모두 적용되어있다면, 적어도 하나의 Replica 는 Write 와 Read 명령의 요청을 받게 되는 것이 보장된다. quorum 이 겹치기 때문에 쓰기 이후에 읽기가 보장된다.
Multi 데이터센터 환경에서, LOCAL_QUORUM 은 약하지만 유용한 보장으로서 사용될 수 있다: 같은 Datacenter 내에서 Read 는 가장 최신의 Write 된 데이터를 보여줄 것을 보장한다. 단일 데티어 센터의 클라이언트는 자신에게 Write, Read 하기 때문에 충분한 경우가 많습니다.
만약 강력한 Consistency 가 필요하지 않다면 LOCAL_ONE 또는 ONE 과 같은 Consistency Level 이 가용성, Latency, Throughput 측변에서 장점이 있습니다.
Distributed Cluster Membership and Failure Detection
Replication 프로토콜과 Paritioning 은 클러스터의 어떤 노드가 살아있고 죽었는지를 알고있어야만한다. 그래야만 Write 와 Read 명령어를 최적으로 전달할 수 있다. 카산드라의 노드 생존여부 정보는 Gossip 프로토콜을 기반으로하는 Failure 탐지 메커니즘에 의해서 분배된다.
Gossip
Gossip 은 어떻게 카산드라가 Endpoint Membership 와 Internode 네트워크 프로토콜 버전과 같은 클러스터 부팅 기본 정보를 전파하는지에 대한 것이다. 카산드라 Gossip 시스템에서 노드들은 상태 정보를 자신의것 뿐만 아니라 다른 노드들의 정보들을 교환한다. 이 정보는 (gernatioon, version) 튜플인 Vector Clock 과 함께 버전으로 관리한다. Vector Clock 의 timestamp 는 변하지 않고 버전은 대략적으로 매 초마다 증가한다. 이 논리 클럭은 카산드라 Gossip 이 오래된 클러스터 상태 정보를 무시할 수 있도록 한다.
카산드라 클러스터의 모든 노드는 독립적으로 그리고 주기적으로 Gossip 테스크를 수행한다.
- 로컬 노드의 HeartBeat 상태를 업데이트하고 Cluster Gossip endpoint 상태를 구축한다.
- 무작위로 클러스터의 노드를 선택하여 Gossip Endpoint 를 교환한다.
- 접속할 수 없는 노드에 Gossip 을 시도한다.
만약 사용자가 카산드라 클러스터를 추엄 구동하면 Seed 노드를 지정한다. 어떠한 노드도 Seed 노드가 될 수 있다. Seed 노드와 Non-seed 노드의 차이점은 Seed 노드는 다른 Seed 노드 없이 Ring 에 구동될 수 있다. 게다가 클러스터가 구동된 후에 Seed 노드는 Gossip 을 위한 Gotspot 이 된다.
Non-Seed 노드는 클러스터에 구동되기 위하여 적어도 하나의 Seed 노드에 접촉해야하기 때문에 Datacenter 하나당 하나의 Seed 노드를 지정하곤한다. Seed 노드는 종종 off-the-shelf 서비스 Discovery 메너키즘을 위해 선택되곤한다.
또한 현재 Gossip 은 Metadata 와 Schema 버전 정보를 전파한다. 이 정보는 데이터 이동과 Schema pull 에 사용된다. 예를들어 만약 노드가 Gossip 상태 중에 일치하지 않는 Schema 버전을 찾게 된다면 다른 노드와의 Schema 동기화 작업을 스케쥴링한다. Gossip 을 통하여 토근 정보도 전파되기 때문에 어떤 Endpoint 가 데이터를 가지고 있는지 또한 노드에게 알려준다.
Ring Membership and Failure Detection
Gossip 은 Ring membership 의 기틀을 구성한다. 그러나 Failure Detector 는 노드가 UP 또는 DOWN 에 대한 완전한 결정을 만든다. 카산드라의 모든 노드는 Phi Accrual Failure Dector 를 실행한다. 이는 모든 노드가 근처 노드가 살아있는지 죽어있는지에 대한 독립적인 결정을 만든다. 이 결정은 주로 노드가 받게되는 Heartbeat 상태에 기반한다. 예를들어 일정 기간동안 Heatbeat 를 받지 못하게 되면 Failure Dector 는 그 노드를 "Convicts" 하고 Read 요청을 더 이상 그 노드로 보내지 않게 된다. 만약 노드가 다시 Heatbeat 을 보내게 되면 카산드라는 연결을 시도하고 성공하면 가용 성태로 변경한다.
Incremental Scale-out on Commodity Hardware
카산드라는 요청량과 데이터 사이즈의 증가에 따라서 Scale-Out 에 적합하다. Scale-Out 은 Ring 에 추가적인 노드를 더하는것이고 모든 노드 추가는 선형적인 컴퓨팅 성능과 데이터 저장소의 증가를 가져온다. 비교하여, Scale-Up 은 이미 존재하는 노드의 Capacity 를 증가하는 것이다. 카산드라 또한 Scale-Up 을 할 수 있다 그리고 특정 환경에서 선호된다. 카산드라는 Sclae-Up 과 Sclae-Out 을 상황에 따라 선택할 수 있는 유연성을 제공한다.
카산드라가 Dynamo 의 주요 관점중의 하나는 호환되는 하드웨어에서 동작하는 것을 시도한다 그리고 많은 기술적 선택을 가정하에 선택할 수 있도록 한다. 예를들어 카산드라는 언제든지 노드에 장애가 발생할 수 있다고 가정하고, CPU 와 메모리 자원을 효율적으로 사용할 수 있도록 저절로 개선한다.
출처 - https://cassandra.apache.org/doc/latest/cassandra/architecture/dynamo.html