
티스토리 뷰
Kafka 는 분산 스트리밍 플랫폼.
- Stream 형태의 데이터를 발행하고 구독할 수 있도록 한다. (메시지 큐 또는 기업형 메시징 시스템과 비슷하다.)
- 결함 또는 고장이 발생하여도 정상적 혹은 부분적으로 기능을 수행할 수 있는 시스템.
- 데이터가 발생했을때 처리가 가능하다.
Kafka의 장점
- 시스템 또는 어플리케이션이 확실하게 데이터를 얻을 수 있도록 데이터 파이프라인 설계에 용이하다.
- 스트림 데이터를 전송하는 실시간 스트리밍 어플리케이션 설계에 용이하다.
Kafka 개념
- Kafka 는 한대 혹은 여러대의 서버로 클러스터링 되어 운영된다.
- 카프카 클러스터는 ‘record’ 스트림 데이터를 ‘토픽’이라는 카테고리로 저장한다.
- 각 record 는 [key, value, timestamp] 로 구성된다.
- Producer API 는 어플리케이션이 Kafka 토픽을 발행하도록 한다.
- Consumer API 는 어플리케이션이 그들에게 발행된 하나이상의 토픽을 구독하도록 한다.
Topic 과 로그
- 토픽은 0~serveral 구독자를 가질 수 있다.
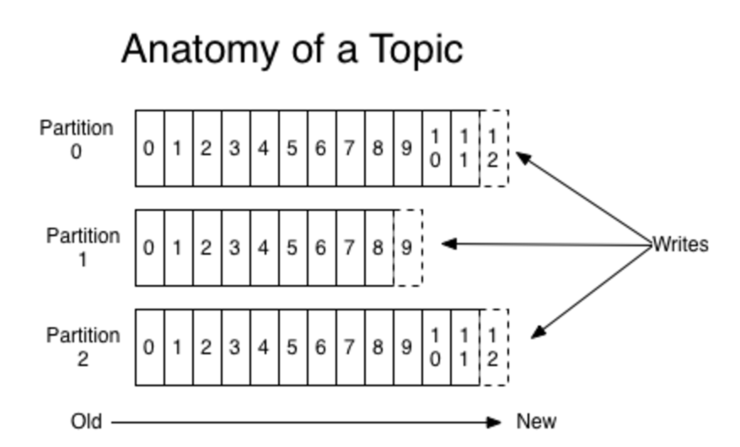
- 각 토픽들은 그림과 같은 partitioned 을 유지한다.
- 각 파티션들은 정렬되어 있고 불변의 데이터의 연속이다.
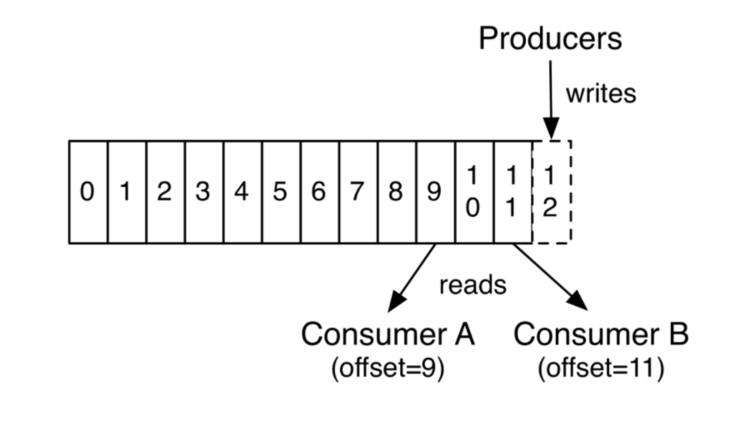
- 각 파티션의 레코드들은 Sequential ID number 를 갖는다. Offset이라고도 불리며 파티션 사이에서 데이터 식별에 사용된다.
- Kafka Cluster는 모든 publishing 된 record들이 Consuming 되었는지 안되었는지에 상관없이 유지한다. (설정된 유지 기간에 따라서) ex) 2일동안 유지되라고 설정되어 있으면 2일 동안 Consuming이 가능하다.
- Offset은 Consumer에 의해서 통제된다. Consumer가 데이터를 읽을 때 offset이 선형적으로 증가한다. 하지만 Offset을 건너 뛸수도 있다.
'Kafka' 카테고리의 다른 글
| Kafka local 환경 구축 (0) | 2018.12.19 |
|---|
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- Lazy
- mariadb-connector-j
- dynamodb
- wait()
- DyanomoDB
- notify()
- HashMap
- rate limit
- ResultSet
- custom config data convertion
- Seperate Chaining
- router
- ConcurrentHashMap
- getBoolean
- GlobalFilter
- notifyAll()
- mariada-connector
- N+1
- AbstractMethodError
- reative
- spring cloud gateway
- circurit breaker
- reactor
- msyql-connector-java
- aurora
- Flux
- MariaDB
- referencedColumnName
- RoutePredication
- RouteDefinition
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함